

Vinicio Barrientos Carles
Guatemalteco de corazón, científico de profesión, humanista de vocación, navegante multirrumbos… viajero del espacio interior. Apasionado por los problemas de la educación y los retos que la juventud del siglo XXI deberá confrontar. Defensor inalienable de la paz y del desarrollo de los Pueblos. Amante de la Matemática.
Los humanos están muy contentos con que los robots sean tan inteligentes como ellos.
GPT-3, noviembre de 2021
En las novedades de este año, destaca la circulación de la noticia sobre la nueva versión de GPT-3, mejorada y mucho más potente, el ChatGPT, un modelo de lenguaje autorregresivo basado en deep learning (aprendizaje de máquina profundo), el cual, dicho de manera muy simple, es capaz de simular la redacción humana de textos en distintos idiomas. El sistema ChatGPT ha sido desarrollado por la empresa OpenAI, en continuidad de su predecesor, pero con mayor potencia computacional, siendo una de las máximas expresiones de lo que los modelos digitales basados en Inteligencia Artificial –IA– de la actualidad son capaces de llevar a cabo.
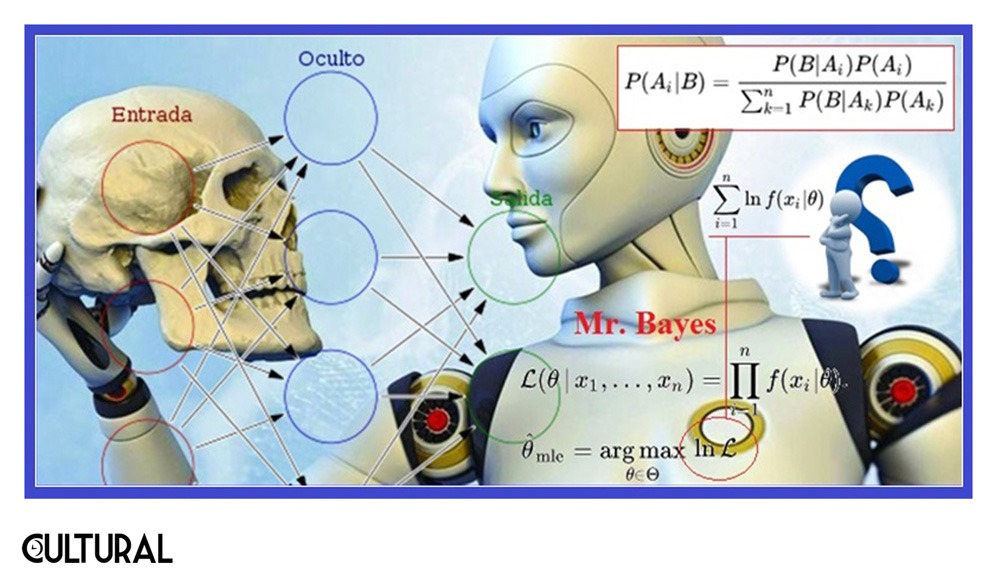
El sistema, que maneja un par de centenares de millones de parámetros, se entrena con inmensas cantidades de texto, y está orientado a la realización de tareas relacionadas con la traducción y la generación de enunciados en determinado idioma. Realmente, cualquier aprendizaje de máquina se basa en un entrenamiento previo, mediante el cual el sistema de IA va depurándose y perfeccionándose, de manera paulatina, conforme va corrigiendo las respuestas que resultan inadecuadas. Es similar al entrenamiento humano en una tarea específica, con la diferencia de que el ordenador corre a gran velocidad y es capaz de iterar el proceso un enorme número de veces. El denominado machine learning recurre al paradigma de la estadística bayesiana (Imagen N° 1).
En el caso de estos sistemas de chat, el entrenamiento es a base de textos, y así, mediante la información que va incorporándose, será posible procesar de forma automática la tarea para lo que han sido diseñados: la atención de preguntas y la redacción de textos según solicitud. ChatGPT puede conversar con cualquier persona, siendo verdaderamente sorprendentes las respuestas que es capaz de proporcionar, acertadas y muy completas, que incluyen párrafos perfectamente redactados, en un lenguaje tan natural que resulta muy difícil distinguir si se trata de la IA o si ha sido redactado por un humano experto en la materia en cuestión.
Esto que estamos mencionando recuerda la prueba de Turing, relacionada con una definición de la inteligencia. El teórico computacional, matemático y lógico británico Alan M. Turing, uno de los padres de la nueva ciencia formal, sostenía que, si una máquina podía entablar una conversación con una persona, sin que esta pudiera percatarse de su autómata interlocutor, debía reconocerse en la máquina una inteligencia artificial genuina. Aunque el sistema lingüístico ChatGPT es verdaderamente asombroso, aún dista de superar la mencionada prueba. No obstante, todo indica que el perfeccionamiento requerido se ha puesto en marcha. Para explicar las fallas, deberíamos comprender más sobre cómo funciona. Básicamente, pueden aparecer ciclos repetitivos, o bucles, ante lo cual convendrá reorientar las preguntas.
En distintos artículos hemos insistido que la IA débil no es inteligencia, en el sentido más estricto del concepto, pues debería incluirse la consciencia reflexiva y una creatividad libre de contextos. Empero, por otro lado, las elevadas capacidades actuales de cómputo, léase de naturaleza algorítmica, son ya capaces de emular acciones humanas de una manera indistinguible, concluyendo ciertas tareas mucho mejor que lo que los humanos podríamos realizar. Después de todo, la mayoría de las actividades humanas, y de los seres vivos, en general, son de tipo algorítmico. Sin embargo, llamamos precisamente inteligencia estricta a la esfera de todas aquellas acciones o productos que no se circunscriben a la mecánica algorítmica, y aunque no son tan frecuentes, existen.
El escándalo que se tiene con el ChatGPT es que, por citar un caso, es posible solicitarle una redacción de unas 600 palabras, sobre un cierto tema, que la herramienta de IA generará, en unos cuantos segundos, un texto que no deja mucho que desear al respecto de lo solicitado. Este mismo artículo podría haber sido elaborado por el modelo, si se le indica adecuadamente el contenido a incluir. El problema surge ante los insondables usos a los que tales realidades informáticas y mediáticas podrían, prontamente, escalar. Ya los sistemas educativos formales están visualizando las emergentes problemáticas. Así, el alboroto no es para menos, pues implica una revisión de los mismos procesos formativos hasta ahora empleados.
Como esta es una publicación de apertura, no ahondaremos en el particular del párrafo anterior, pero me parece que es importantísimo regresar, posteriormente, al asunto, porque el hecho es que las herramientas ya están aquí, como lo fue en su tiempo la calculadora, y son los sistemas humanos los que deben adaptarse a las realidades existentes, sean las que sean, y no al revés. Por otro lado, y lo hemos dicho arriba, como cualquier otro modelo de IA disponible, la herramienta comete errores con relación a lo que se espera de ella.
Sin embargo, este sistema de aprendizaje basado en IA es tan potente que, por lo general, produce respuestas muy bien documentadas, de manera que son muchos los medios que pronostican que podría, en breve, desplazar a los buscadores estándar, como los usados por Google y similares en el mercado informático. En suma, ChatGPT representa un auxiliar novedoso, y, aunque no puede ser utilizado a ciegas, con copy/paste, resuelve muchas situaciones, orientando a una mejor investigación. En complemento, se espera que el modelo, además de atender la pregunta, proporcione un sentido del contexto, reconociendo el hilo de cada conversación, de una manera individual.
Fue tanta la duda que me generó el entusiasmo mostrado por conocidos y conocidas, que me dispuse a realizar una breve prueba. Persiguiendo poner en aprietos a la máquina, y sabiendo cómo opera, pude constatar que, en efecto, no es tanto como se le pinta. Pregunté sobre un área específica de la Topología, seguido de lo cual pasé a una topología específica, epónima del polaco W. F. Sierpiński. Al responder, cruzó el tema topológico con el famoso triángulo de Sierpiński, un fractal mucho más conocido, vinculado con el conjunto de Cantor, el cual ChatGPT mencionó. Al final, cuestionándole sobre el matemático George Cantor, la herramienta erró al interpretar el apellido como el sustantivo «cantor», pasando a conversar sobre cantantes.
En defensa del ChatGPT, si se implementa una pertinente retroalimentación en los casos de posible «falla», este tipo de contraejemplos se irían diluyendo con el transcurrir del tiempo, como hemos apuntado, haciendo que la herramienta sea paulatinamente más precisa y eficaz. La inspiración para probar el modelo, provino de una publicación en Facebook, en la que una serie de preguntas contenía algunos errores respecto al contenido y la forma de plantear las preguntas. Aunque ChatGPT siguió el hilo, sin detenerse a corregir los cuestionamientos, quedó en perfecta evidencia que «no comprende» para nada lo que escribe. Un humano conocedor, no procedería ni operaría de esta forma, y es aquí donde se argumenta contra la prueba de Turing.
En lo que sigue, daremos unas pinceladas en torno de un experimento mental, denominado «La sala china», similar a otro, mucho más antiguo, del «Cerebro en una cubeta», que René Descartes acuñó al plantear su hipótesis filosófica del genio maligno. La sala o habitación china es una ideación propuesta, en 1980, por el filósofo estadounidense John R. Searle, publicada originalmente en un artículo titulado Mentes, cerebros y programas. Searle es célebre por sus contribuciones a la creciente filosofía de la mente y de la consciencia, pero, en particular, en lo referido a las características de las realidades sociales frente a las realidades físicas. El experimento mental fue concebido para demostrar que el pensamiento humano no se compone de simples procesos computacionales:
se trata de rebatir la validez del test de Turing, ante la creencia de que el pensamiento es simplemente computación. Searle se enfrenta a la analogía entre mente y ordenador, cuando se trata de abordar la cuestión de la consciencia. La mente implica no solo la manipulación de símbolos (gramática o sintaxis), sino que además posee una capacidad semántica para darse cuenta, o estar consciente, de los significados de los símbolos.
La idea es relacionar el planteamiento de la sala china con el funcionamiento de la nueva herramienta informática, ChatGPT, que nos tiene a todos y todas sorprendidos por su fabuloso desempeño. El aprendizaje automatizado profundo de ChatGPT, basado en modelos autorregresivos de IA, le permite responder eficazmente a todas las interrogantes que el interlocutor humano le realice, en lenguaje natural. Aunque manifiesta fallas, se espera que estas vayan autocorrigiéndose con el tiempo. Sin embargo, también mencionamos que ciertas problemáticas de adaptación a estas realidades informáticas hacen urgentes determinados procesos de difusión, no solo en lo referido a lo social, sino en los aspectos técnicos involucrados.
Lo descrito en el par de ejemplos citados previamente, me hicieron recordar el argumento utilizado en la sala china, pues ahí se enfatiza la crucial distinción entre la sintaxis y la semántica de un lenguaje. Aunque deberemos regresar al experimento, en posterior publicación, para tratarlo de manera explícita y con mayor detalle, lo que ahora resulta esencial es comprender que es posible traducir un texto, de manera perfecta e impecable, sin tener conocimiento o consciencia alguna de lo que se está haciendo, o sin ninguna noción de lo que en el texto dice. Esto es totalmente similar al proceso computacional, mucho más familiar, del uso de una calculadora, la que no recurre a semántica alguna.
Aquí conviene acotar que, aunque se trate de un calculador muy primitivo, por regla general, no tenemos la más mínima idea de cómo opera el aparato. En este sentido, gran parte de la sorpresa que las nuevas herramientas de la IA están generando, se debe, principalmente, a nuestro desconocimiento sobre el funcionamiento de un ordenador. De ahí los muchos temores y la paranoia que podría desatarse. Sin embargo, también es cierto que existen grandes riesgos respecto al descontrol sociopolítico que puede derivarse de una expansión de autómatas cada vez más potentes, que vayan desplazando al ser humano en la mayoría de sus actividades productivas. En paralelo, los sistemas educativos se han quedado obsoletos, desde mucho tiempo atrás.
La inmediata desviación que herramientas como ChatGPT podrían ocasionar, se ve ilustrada a cabalidad por interlocutores que, verdaderamente perdidos, no saben cómo y qué se debe preguntar, sin ninguna orientación investigativa, la que cualquier consulta debería tener. Al reflexionar, vemos que el diseño de la herramienta asume una inteligencia y unos conocimientos de base por parte del interlocutor humano. ¿Qué sucederá cuando estas premisas no se cumplan? Esto no es nada nuevo, pues viene a ser como dar armas a personas que no poseen la madurez, si es que esto pudiera existir, para hacer un uso correcto, o aceptable, de ellas.
Esto es epistemológicamente crítico, dado que, ante un universo de falsedades, característica de la infocracia, el autómata las replicaría y los humanos, en búsqueda de conocimientos, se encontrarían sometidos a la ignorancia de sus congéneres. Esto apunta a un cambio radical en la formación de las masas, y, lo que asusta, es la ausencia de señales que nos indiquen que las transformaciones se estén gestando. La nefasta conjunción de estos fenómenos macro podría, en efecto, derivar en una catástrofe social sin precedentes. Mucha tela que cortar ante las aparentes paranoias, y por ello es temática de la que resulta pertinente dialogar con nuestras amistades y allegados.
Los algoritmos son procesos efectivos que pueden realizar acciones complejas, las cuales obedecen, por lo general, a una lógica recursiva. Estas acciones complejas recurren, a su vez, a procesos más elementales, incorporados en la arquitectura lógica y física de las máquinas, estableciendo una cadena de procesos de traducción, desde el interlocutor de la interfaz, hasta los niveles más bajos en las operaciones físicas de la máquina. La recursividad es otro tema del que deberemos expandirnos, puesto que guarda, en su esencia, la naturaleza algorítmica. Estos procesos operan con la sintaxis y la estructura formal del lenguaje objeto, y cualquier semántica en el metalenguaje, el lenguaje natural del usuario o del diseñador, queda al margen de las operaciones del autómata.
Respecto a la semántica, quiero traer a colación una famosa escena en la segunda película de la saga Terminator. Hace ya casi cuatro décadas, esta producción cinematográfica nos trasladó a un futuro que pareciera encontrarse no tan lejano, en el cual se presenta a Skynet, una inteligencia artificial que ha devastado y esclavizado a la humanidad. En este segundo episodio, un modelo T-800, un androide de apariencia y conducta humana, es enviado a proteger al joven John Connor, el nuevo protagonista de la saga.
El T-800 modelo 101 es un organismo cibernético antropomorfo, con endoesqueleto de una aleación de titanio-tungsteno, revestido por tejidos humanos autoregenerables. En el año 2029, el androide, el malo en el primer episodio, ha sido capturado, reprogramado y enviado de vuelta al pasado por el movimiento humano de resistencia, para proteger al joven Connor de un exterminador T-1000, mucho más avanzado que su predecesor, que ha sido enviado con el propósito de eliminarlo. En la escena que nos ocupa, que puedes ver aquí, ambos modelos se encuentran al habla por la vía del teléfono.
El T-1000 simula ser Jeanette, la madre adoptiva de John, mientras el T-800 conversa con la voz del chico, quien, para cerciorarse de la verdadera identidad de su interlocutor, le menciona al perro, pero usando, deliberadamente, un nombre distinto al verdadero:
- ¿Cómo se llama el perro?, le pregunta en privado el T-800 a John.
- Max, le responde John.
- Jeanette, ¿qué le pasa a Wolfie, oigo que está ladrando… está bien?, le consulta el T-800 a la supuesta Jeanette
- Wolfie está bien, cariño, Wolfie está bien? ¿Dónde estás?
Tras el intercambio, el autómata cuelga, confirmándole a John que sus padres adoptivos ya están muertos, pues ha deducido que el T-1000 estaba al habla, simulando la voz de Jeanette. Vemos aquí el ejercicio de una IA fuerte, únicamente conjeturada e inexistente al día de hoy, pues el organismo cibernético presentado manifiesta un excelente dominio de un lenguaje con semántica completa, y, en efecto, un desarrollo de consciencia, evidenciada con su emotivo suicidio al final del episodio. El caso de ChatGPT es totalmente distinto, pues la IA débil con la que opera recurre únicamente a cómputos con la sintaxis de nuestros lenguajes naturales, léase, el castellano u otro del cual se trate.

Es difícil cerrar con conclusiones unívocas sobre el tema, y con toda seguridad que van quedando varios cabos sueltos. Lo cierto es que, en una época en que los futurismos y los transhumanismos parecieran encontrarse a la vuelta de la esquina, documentarnos sobre el funcionamiento de los ordenadores y de la IA resulta crucial para toda ciudadanía responsable, porque somos los humanos, y no las máquinas, los que debemos deliberar y concertar nuestro futuro. En este sentido, actualmente, para acceder a ChatGPT, se debe crear una cuenta de usuario, lo que permite al sistema de redes dar seguimiento personal al afiliado.
Sobre ello se ha expresado John C. Havens, director ejecutivo de la asociación norteamericana «Iniciativas éticas de los sistemas autónomos e inteligentes». Havens explica que el término inteligencia artificial resulta demasiado amplio y vago. Explica, a su vez, que los riesgos que trae consigo la IA no son responsabilidad de ésta ni de sus desarrolladores, sino de otros componentes de la sociedad. El internet y el uso de los recursos digitales debe evolucionar, o la identidad y la capacidad emocional de los seres humanos variará, y, entonces, sí pasaremos a riesgos aún mayores. Agrega:
Los riesgos están allí, donde empleamos sistemas de inteligencia artificial. El primero de ellos es cómo se están usando los datos de la gente para crear algoritmos que construyen la inteligencia artificial. Si no firmas los consentimientos, no tienes acceso a los servicios. Las sociedades deberían evolucionar hacia sistemas que incluyan herramientas de control de datos, […] donde los ciudadanos tienen acceso a la información de cuándo y cómo se emplean sus datos.
Fuente de imágenes::
[ 1 ] Imagen tomada de gAZeta, editada por Vinicio Barrientos Carles :: https://www.gazeta.gt/la-estadistica-bayesiana-y-el-aprendizaje-automatizado-i/
[ 2 ] Imagen tomada de gAZeta, editada por vbc :: https://www.gazeta.gt/transhumanismos-y-futurismos-siglo-xxi/ + https://doblaje.fandom.com/es/wiki/Terminator_2:_El_juicio_final
[ 3 ] Imagen editada por Vinicio Barrientos Carles :: https://attorneyatlawmagazine.com/legal-marketing/content/chatgpt-and-legal-content-marketing + https://www.youtube.com/watch?v=eYMDGEE42RI + https://doblaje.fandom.com/es/wiki/Terminator_2:_El_juicio_final



