
Vinicio Barrientos Carles
Guatemalteco de corazón, científico de profesión, humanista de vocación, navegante multirrumbos… viajero del espacio interior. Apasionado por los problemas de la educación y los retos que la juventud del siglo XXI deberá confrontar. Defensor inalienable de la paz y del desarrollo de los Pueblos. Amante de la Matemática.
Lo que vemos cambia lo que sabemos. Lo que conocemos cambia lo que vemos.
Jean Piaget
El titular de esta oportunidad es uno que se venía quedando en el baúl de las reservas, desde hace varios años, después de inaugurar la temática con el artículo «La estadística bayesiana y el aprendizaje automatizado». El objetivo de esa primera publicación era el de vincular el denominado machine learning –ML–, que traducimos como aprendizaje automatizado (en las máquinas), con el paradigma estadístico bayesiano. Hoy estaremos compartiendo algunos elementos del deep machine learning –DML–, abreviado y traducido simplemente como aprendizaje profundo. Empero, esta abreviación deriva en varias reflexiones, pues utilizamos unas palabras que poseen un particular y específico significado en el contexto humano, entiéndase, «aprendizaje» y «profundo».
En este sentido, nos percatamos del impacto que estamos teniendo con el advenimiento de la inteligencia artificial –IA–, por lo dicho en el párrafo anterior, que términos, palabras y conceptos, que antes se encontraban restringidos al ámbito del desempeño humano, cotidiano o laboral, de los seres concebidos inherentemente como inteligentes, o bien, si se quiere ampliar, a los organismos vivos con una mente mejor desarrollada, ahora, para sorpresa general, los encontramos con referencia a las respuestas que los autómatas, las máquinas y los ordenadores artificiales realizan.
Aunque repitamos que los llamados smart phone no son verdaderamente «inteligentes», cuestión que hemos insistido en varias publicaciones previas, como en «La IA débil no es inteligencia», la verdad es que una sensación subyacente persiste en la voz popular, la que no desaparece tan fácilmente, a saber: que las máquinas están tomando el control de nuestras vidas. Nuevamente, las inquietudes nacen, crecen y se reproducen a raíz del despertar de las curiosidades que ha levantado el ChatGPT. Como bien reza la máxima, la curiosidad es madre del aprendizaje. En «Expectativas y realidades del ChatGPT» apuntábamos:
En las novedades de este año, destaca la circulación de la noticia sobre la nueva versión de GPT-3, mejorada y mucho más potente, el ChatGPT, es un modelo de lenguaje autorregresivo basado en deep machine learning (aprendizaje de máquina profundo), el cual, dicho de manera muy simple, es capaz de simular la redacción humana de textos en distintos idiomas.
Para empezar, será conveniente puntualizar que la IA hace referencia a todo tipo de herramientas computacionales que permiten llevar a cabo acciones que revisten, para nosotros, determinado grado de inteligencia, aparente o real, puesto que corresponden a ciertas actividades que usualmente han venido siendo atribuidas, o reservadas, a los seres humanos. Si se pone atención, la distinción entre lo que es aparente y lo que es real establece una diferencia radical, es decir, desde la raíz. Esta distinción fundamental en el desempeño y la respuesta obtenida de una máquina establecerá una clasificación esencial para la IA, la que debemos tener siempre presente.
En efecto, la diferenciación estriba en separar aquellos procesos inteligentes, producto de una mente como la humana, de aquellos que únicamente simulan un cierto grado de inteligencia, pero que realmente corresponden a un elevado desempeño computacional, que nos sorprenden, dada la inmensa cantidad de información procesada de una manera increíblemente rápida, que nos parecen instantáneos. Esta es la distinción usual entre la hipotética IA fuerte, o general, y la IA débil o estrecha, que también suele denominarse inteligencia computacional, pero que, como estamos subrayando, corresponde únicamente a proceso algorítmicos de muy elevado rendimiento.
La IA fuerte –IAF–, o IA general –IAG–, no existe en la actualidad, y en las últimas seis décadas que lleva el proyecto para su construcción, se han tenido fracasos, en varios aspectos, para su efectivo desarrollo. En términos muy generales, la complejidad que demuestra poseer el cerebro humano, u otro más simple aún, dista mucho de los modelos implementados de IA, lo que conduce a pensar que la llamada singularidad —superinteligencias artificiales basadas en réplicas del cerebro que superarán con mucho la inteligencia humana— es una predicción con muy poco fundamento científico. Es un salto de fe que pareciera más producto del entusiasmo humano, de su ambición, que de sus competencias productivas.
Sobre esto último conversamos algo en «Los monstruos del poder y el ChatGPT», en donde citábamos «Surgido de la vanidad humana, mezclada con la ciencia y la ambición, acabaría por aniquilar a su creador», palabras de Mary Wollstonecraft Shelley, autora de la novela Frankenstein o el moderno Prometeo, escrita hace dos siglos, en 1818. Sobre la obra y el trasfondo, la colombiana Melba Escobar recuerda palabras del preámbulo: ¡Qué peligroso puede resultar el conocimiento! En el citado artículo escribimos:
Por otro lado, la escritora colombiana esboza, como en el ir y venir de un péndulo oscilante, las similitudes de dos momentos, separados por dos siglos, vinculándolos con gran precisión. La correlación que establece entre el monstruo de la novela de Shelley, a inicios del siglo XIX, y la herramienta de inteligencia artificial del ChatGPT, de la actualidad, describe la vinculación que ata a estos «monstruos» con la ambición humana, que, en la persecución del poder de aquello, posiblemente inefable, no evalúa las consecuencias de las creaturas de construye.

Todo esto para matizar los impactos y las nebulosas que circulan por nuestras mentes en torno de una posible problemática. En la publicación «¿Desplazará la IA al ser humano?» hemos insistido en varias de nuestras conclusiones: que no se trata de la tecnología o los avances, que deben ser bienvenidos, sino en la respuesta apropiada y la reorganización de los sistemas sociopolíticos humanos los que deben estar a la altura de la celeridad de los vertiginosos cambios. No se trata de las máquinas y los autómatas, de trata de nosotros y nuestra falencia humanas, sociales, económicas y de toda índole las que deben ponerse al día, de acuerdo a las exigencias de los nuevos tiempos.
Sobre nuestras acciones ante el cambio, pero, ante todo, ante los temores de ser reemplazados por los autómatas, hemos compartido el artículo prescrito, con la interrogante crucial: ¿desplazará? Sobre el ChatGPT, Melva Escobar, en su artículo «Frankenstein», dirigiéndose al lector y lectora, le hace la siguiente pregunta:
¿Qué les hace pensar que este texto no ha sido escrito por una herramienta tecnológica y no por una persona? Claro, todo depende de cómo definimos a una persona, pues hasta ayer se pensaba que la conversación y el diálogo eran facultades exclusivas de la condición humana [pues] ya nos han dicho que los carros se manejarán solos, los psicólogos podrán ser suplantados por aparatos, lo mismo que los artistas, los escritores, los traductores, y, en fin… ¿Qué oficio no será copado por las máquinas?
Dejando de lado, en suspenso, al menos por ahora, las reflexiones sobre los significados de los conceptos «aprendizaje» y «profundo», la idea central será la de atender posibles dudas en personas que no son especialistas en estos tópicos, quienes, de repente, están imaginando situaciones muy en correspondencia con lo que, para nosotros, los humanos, podrían significar las palabras mencionadas. Después de todo, hace apenas veinte años, una gran cantidad de la población humana, con fuertes tendencias y predilecciones por las humanidades, las ciencias sociales o las ciencias del espíritu, como les denominara el filósofo y sociólogo alemán Wilhelm Dilthey, nunca imaginaron que deberían sumergirse en los aspectos formales y tecnológicos relativos a la informática y la computación
En complemento, podemos aportar unas someras conclusiones, aunque útiles y fáciles de aplicar en medio de esta maraña de nuevos conceptos. Primero, estar claros que, de todo lo que se concibe como IA, una parte es IA débil (IA computacional), y de esta, solo una parte, la que se encuentra funcionando en la actualidad: la IA estrecha o específica. Por ello, cuando te mencionen herramientas de IA, recuerda que no se trata de inteligencia real, sino únicamente de inteligencia aparente, puesto que no se cumplen las condiciones que pasaremos pronto a enlistar.
Por otro lado, la IA actual contiene, como una parte muy desarrollada, estas herramientas del machine learning –ML–. Después, entre estas herramientas de aprendizaje automatizado, algunas, solo algunas, podrán ser consideradas de aprendizaje profundo, esto es, DML (deep machine learning). Los chatbot, desarrollados para realizar diálogo con humanos, en lenguaje natural, correspondes a este tipo de aplicaciones del DML.
¿Qué debería poseer un sistema automatizado y autónomo para ser considerado inteligente? Bueno, antes de dotarle de inteligencia, se ha pensado que una máquina debería poder desempeñarse eficaz y eficientemente en un ambiente como el que confrontamos los seres humanos, es decir, es altamente deseable que goce de los subsistemas requeridos para su movilidad y los sensores necesarios para la interacción efectiva con su entorno. Empero, esto está relacionado con la robótica y la cibernética, de manera que, aunque aparece con frecuencia en la cinematografía, no refiere exactamente a aspectos de la IA. Por otro lado, una mente artificial, para ser considerada inteligente, debería evidenciar en su desempeño, cuando menos, las siguientes características:
- a) Poseer y saber aplicar una capacidad lógica deductiva, que atienda las realidades inmediatas y a mediano plazo del entorno que le circunda.
- b) Realizar procesos de toma de decisiones, no preestructurados, ante situaciones novedosas o no antes atendidas, lo que incluye la planificación de escenarios a futuro.
- c) Desarrollar técnicas y metodologías de aprendizaje no programado, que le permitan desarrollar conocimiento del mundo y acción bajo ciertos principios racionales y de optimalidad.
- d) Establecer pertinentes subsistemas de comunicación, propios, desarrollando lenguaje e incorporando las capacidades idóneas para comunicarse eficientemente con otro tipo de agentes inteligentes.
Aunque cada uno de estos requisitos representa un reto en sí mismo, y sabiendo que tal utópica realidad, la denominada singularidad computacional, llevando a los autómatas más allá de la frontera de Turing Church, no se ha producido, conviene apuntar que ha habido más avance en un área, o finalidad, que en otra. La IA estrecha o específica que se ha venido desarrollando ha alcanzado avances muy significativos en lo concerniente al inciso c, el aprendizaje de máquinas, sobre todo en la década reciente. Primero deberemos comprender a qué hace alusión este aprendizaje de máquinas. Básicamente, que un autómata aprenda implica y requiere que posee una mejora paulatina y sistemática en su respuesta ante una misma pregunta.
No todo cómputo es inteligente, es decir, un cómputo, cálculo o programa dará, por lo usual, la misma respuesta a una misma pregunta. Si esto no sucediera, significaría que la máquina está aprendiendo de sus desempeños. Esto conlleva una ampliación del sentido inicial del determinismo computacional, que procesa siempre de la misma forma las entradas, a menos que tenga procesos recursivos que le permitan modificar su propia programación, esto es, algún tipo de meta algoritmia que opere sobre los algoritmos inicialmente entregados. Así, el ML representa una mejora en el desempeño, pues el autómata podrá ir cambiando sus respuestas conforme vaya «aprendiendo de sus errores».
¿Cómo se realiza este proceso de mejora paulatina? Bueno, uno de los primeros pasos es operar con sistemas probabilísticos que vayan evolucionando hacia otro mejores, no por la programación, sino por la calidad de la información de entrada. En el artículo sobre el paradigma estadístico bayesiano y el aprendizaje automatizado de una máquina, explicábamos la evolución de los sistemas para enfrentar la incertidumbre natural del mundo. Específicamente, al referirnos a la mejora sobre el desarrollo inicial de la IA, basado y conducido desde un paradigma de programación de tipo determinista (en sentido estrecho), es decir, aquella que se realiza a través de una serie de instrucciones de control, de tipo condicional, las cuales representaban el conocimiento de los expertos (humanos) en una determinada materia, escribíamos:
[ … ] el modelaje de escenarios complejos de nuestro «mundo real» exigió ir más allá de los lenguajes formales construidos a partir de un elemental «if, then, else». Así, emergió un área de la IA enfocada en el desarrollo de sistemas que podrían aprender y autodesarrollarse a partir de unos procesos iniciales básicos. El machine learning, en lugar de indicar explícitamente cómo resolver un problema, creará soluciones temporales (parciales), de manera que pueda ir generando mejores soluciones por medio de los ejemplos (casos) con los que va interactuando, tomando decisiones mediante predicciones basadas en el uso de métodos de inferencia lógica y del enfoque estadístico bayesiano.
La mejora se produce desde el momento en que la estadística bayesiana es de naturaleza intrínsecamente inductiva, empirista, pues parte de los casos y ejemplares conocidos, para realizar predicciones sobre lo desconocido, lo cual resulta muy apropiado en las ciencias sociales o en la vida cotidiana, entiéndase, en la interacción con los humanos. A diferencia del enfoque bayesiano, la estadística frecuentista se basa en el concepto de distribución de frecuencia, el cual tiene severos problemas para ser aplicados en la práctica, bajo escenarios de ignorancia profunda. La regla de inferencia básica en el enfoque bayesiano es el teorema de Bayes, y para ilustrar su uso regresamos al ejemplo presentado previamente.
Acá no podríamos explicar el uso y la potencia del teorema de Bayes, pero, si ilustrar cómo es que proporciona una mejora paulatina de los «saberes», conforme transcurre la carga y el análisis de los casos. Después de todo, si se tiene una alta certidumbre de que un hecho seguirá a otro, podemos realizar predicciones altamente efectivas, que darán la sensación de que se sabe a cabalidad de lo que se está hablando, aunque no se entienda una sola palabra de los que se dice.
Es el caso de la habitación china, experimento mental propuesto originalmente por el filósofo de la mente, John Searle, en su escrito «Mentes, cerebros y programas», publicado en Behavioral and Brain Sciences en 1980. En la sala china, el autómata traduce perfectamente el chino, sin entender una palabra de ese idioma, pues lo único que hace es predecir exactamente como debe responder ante un determinado signo del idioma chino, o de otro que quiera colocarse como entrada. Lo único que se necesita es el entrenamiento adecuado. Esta digresión a Searle la hacemos muy a propósito del alboroto mediático del ChatGPT.
Respecto al caso citado, sobre la ilustración del teorema de Bayes, véase la imagen que sigue. Se tiene el siguiente cuadro, en el que se ha registrado a 300 personas, hombres y mujeres, fumadores y no fumadores. El paradigma bayesiano opera, distinguiendo probabilidades a priori, que se dan en ignorancia de datos, y probabilidades a posteriori, que se ven mejoradas, en el sentido que los cálculos son más precisos al disponer y contar con más información.
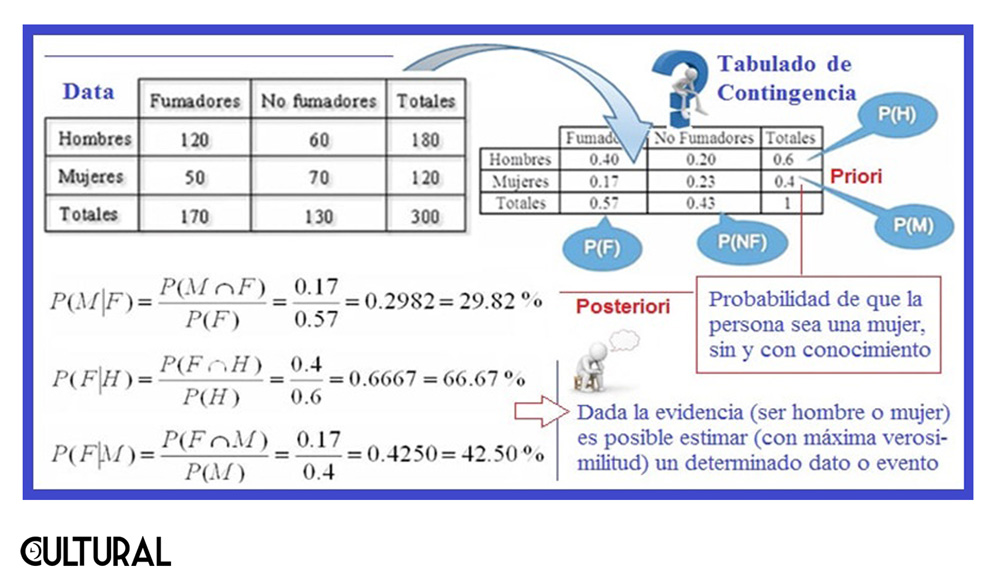
Puede verse, por ejemplo, que la probabilidad de ser fumador, o fumadora, es P(F) = 170/300 = 56.67 % ≃ 57 %, mientras que la probabilidad de ser mujer es P(M) = 120/300 = 40 %. Por otro lado, las probabilidades a posteriori son condicionadas a un conocimiento adicional, y de allí el calificativo a posteriori. Por ejemplo, la probabilidad de que sea fumador, si se sabe que es mujer será P(F|M) = 42.5 %, mientras que la probabilidad de ser mujer, si se sabe que es fumadora será P(M|F) = 29.82 %.
Si se tuviera conocimiento parcial, o menos completo, únicamente se conocerían los totales, esto es, las probabilidades marginales. En esta situación se podría estimar si alguien es fumador o no: P(F) = 57 %, sin distinguir si se trata de un hombre o una mujer. Sin embargo, al alimentar el cuadro con los datos cruzados, las estimaciones mejoran, puesto que, si se sabe que es mujer, tendremos P(F|M) = 42.5 %, mientras que, si es hombre, P(F|H) = 66.67 %. En general, conforme cada caso que se evalúa, la predicción bayesiana será, indefectiblemente, más precisa. Este es el mecanismo para el éxito del aprendizaje automatizado.
Entendiendo el ML, cómo es que una máquina «aprende», la interrogante que sigue pendiente es: ¿a qué se refiere lo profundo? Pues, de una manera superficial (no tan profunda, valga la situación del uso del calificativo), la profundidad computacional está relacionada con una multicapa de aprendizaje. En el artículo «Computación y recursividad» hicimos mención que un algoritmo llama a otros y también a sí mismo, pero estas llamadas no modifican su código o programa inicial, únicamente se iteran y recurren a otros cálculos previos.
Por el contrario, se habla de generación de capas computacionales cuando un programa corre sobre el código de otro programa, esto es, cuando el objeto de un cierto programa es otro programa, lo cual sucede de manera natural en la compilación y otros procesos de bajo nivel. Dicho en otras palabras, si aprender es mejorar la respuesta del ordenador, la profundidad del aprendizaje se refiere a aprender cómo mejorar el aprendizaje, al desarrollar métodos alternativos a los que están siendo utilizados para el aprendizaje.
De alguna manera, por ahora solo intuitiva, la profundidad del aprendizaje refiere a la denominada metacognición (como la entendemos en una mente con consciencia, como la humana), de manera que el aprendizaje multicapas puede mejorar el desempeño para aprender a realizar ciertas acciones. Todos estos conceptos están fuertemente vinculados con las redes neuronales y, en definitiva, lo mejor sería partir de un ejemplo concreto. El caso de los avances en filogenia y la nueva sistemática biológica ilustran muy bien su funcionamiento, por citar una de las tantas áreas en donde el DML ha tenido un impacto positivo en el desarrollo de la ciencia contemporánea. No alcanzaríamos acá a enlistar las bondades.

Respecto a las limitaciones, regrésese a lo que la IA estrecha es, y las reflexiones que hemos realizado sobre el experimento de la habitación china. El hecho de una falencia semántica profunda, sino es que una ausencia total de la referencia, en el sentido utilizado por el matemático y lógico alemán Gottlob Frege, es fundamental para ponderar los límites de este tipo de herramientas. Nuevamente se encuentra en los seres humanos el uso idóneo y responsable de estas nuevas utilerías, como ha sucedido en el pasado, y para ello evóquese el asunto y problemática de las armas, en general.
Algo también queda en claro, y en el tintero: deberemos continuar con todos los tópicos que hemos mencionado o esbozado, en una revisión, ya no tan superficial, sobre qué podemos y qué no podemos esperar de la IA vigente. Cierro con una cita en torno de la novedad del momento, a propósito del lanzamiento de la versión 4.0 del ChatGPT, realizada la semana pasada:
es un prototipo de chatbot de inteligencia artificial desarrollado en 2022 por OpenAI que se especializa en el diálogo. El chatbot es un gran modelo de lenguaje, ajustado con técnicas de aprendizaje, tanto supervisadas como de refuerzo. Se basa en el modelo GPT-3.5 de OpenAI, una versión mejorada de GPT-3. ChatGPT se lanzó el 30 de noviembre de 2022 y ha llamado la atención por sus respuestas detalladas y articuladas, aunque se ha criticado su precisión fáctica. A cinco días de su lanzamiento, OpenAI calculaba que ChatGPT ya tenía más de un millón de usuarios. El 14 de marzo 2023 se lanzó GPT-4.
Fuente de imágenes ::
[ 1 ] Imagen gAZeta, elaborada de varias fuentes por Vinicio Barrientos Carles :: https://www.gazeta.gt/los-monstruos-del-poder-y-el-chatgpt/
[ 2 + 4 ] Imagen gAZeta, elaborada de varias fuentes por vbc :: https://www.gazeta.gt/dml-aprendizaje-automatico-profundo/
[ 3 ] Imagen editada por Vinicio Barrientos Carles :: https://www.gazeta.gt/la-estadistica-bayesiana-y-el-aprendizaje-automatizado-i/




